How to Create a Datastore Snapshot Failsafe
Sometimes this task is harder than it sounds. If your SAN is out of space, or the SAN management tools are out of your control, you could be stuck.
But… follow a simple trick to give yourself that last little bit of wiggle room in the event that a snapshot fills a datastore.
Add a large text file to the root of the datastore that you can delete if you need headroom! I know it sounds too simple… but it’s simple and effective. Plus, if your array de-duplicates and/or compresses data, this trick will cost you virtually no space on the storage.
These directions are updated for modern VMware and Hyper-V environments, but the same concept applies to any hypervisor out there today.
How do you do this?
It’s easy!
VMware Instructions
Enable the SSH server, and remote into one of the ESXi hosts. This example is from a vSphere 6.0 ESXi server from my lab.
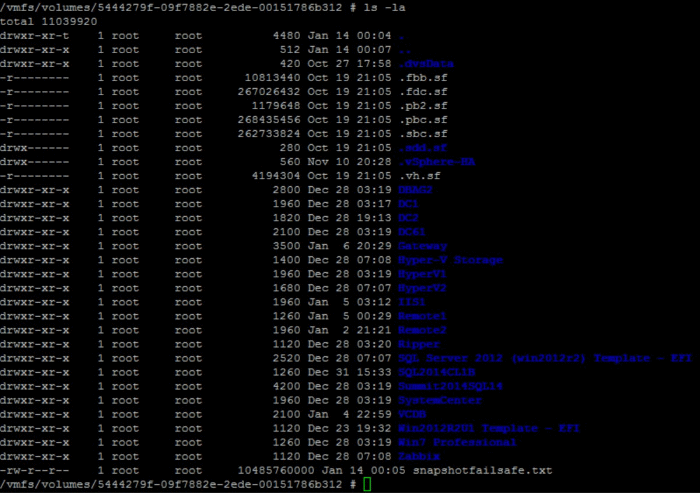
Change directories into the root of the datastore that you want to create the file in. They are located at /vmfs/volumes/.

Use the Linux command ‘dd’ to write a 10GB file (or whatever size of your choosing). Basically, we’re creating a file full of zeroes with a 1MB block size and ten thousand blocks. Simple, eh?
dd if=/dev/zero of=snapshotfailsafe.txt count=10000 obs=1M ibs=1M

It will take a few minutes to create the file. You can see the file creation process with another terminal, and can see the activity in the hosts’ disk performance view in the vSphere Client.

Once done, you’ll see it in the terminal and in the datastore view screen.

Hyper-V Instructions
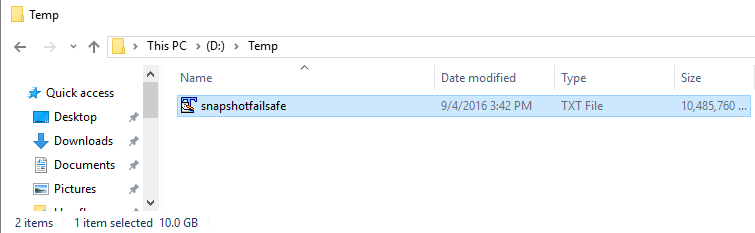
This one is easier. Use the console command fsutil to create a new file quickly on each folder or share used for storing VMs. The following command creates an empty 10GB file on the file system.
fsutil file createnew snapshotfailsafe.txt 10737418240
![]()
Results
If you have a VMware or Hyper-V VM-level snapshot that has filled up or is filling the volume, just browse the datastore and delete the failsafe file! You just gained time to better manage the snapshot or move data around to accommodate the growth.
I know this seems unnecessary, but every virtualization admin seems to get burned with a rogue snapshot once. Occasionally, it’s more than once.
How can I prevent actually needing this?
That part is pretty simple, too. Just set up a Microsoft System Center or VMware vCenter alert to warn you if you have a snapshot that is growing out of control! The directions for VMware on how to do this are located in this VMware KB article. (Just remember to set up the email server so you actually receive the emails!)