 Microsoft’s SQLIO disk benchmarking utility had served the SQL Server community extremely well for many years. However, Microsoft recently deprecated this utility, but released a much improved replacement. Their new storage benchmarking utility, called DiskSpd, as an open-sourced project for the community. This utility provides a more granular storage testing methodology, along with sub-microsecond latency values that are very important with today’s all-flash and hybrid storage devices. DiskSpd is now Heraflux’s preferred method for stress-testing storage devices.
Microsoft’s SQLIO disk benchmarking utility had served the SQL Server community extremely well for many years. However, Microsoft recently deprecated this utility, but released a much improved replacement. Their new storage benchmarking utility, called DiskSpd, as an open-sourced project for the community. This utility provides a more granular storage testing methodology, along with sub-microsecond latency values that are very important with today’s all-flash and hybrid storage devices. DiskSpd is now Heraflux’s preferred method for stress-testing storage devices.
More information about how to use DiskSpd for individual tests can be found here.
Heraflux has created a PowerShell-based batch harness for DiskSpd that allows you to automate the repetitive testing of storage with DiskSpd with multiple test configurations, including iterations of read/write, random/sequential, operations per thread (workload intensity), and read/write percentages per test. The output test results are then converted into a CSV file for you to analyze.
Download the script here.
Download the Excel spreadsheet for quick analysis here.
NOTE: No disk benchmarking utility is a true representation for a database workload on disk, and will not be as effective as real-world database workload replays. We recommend using SQL Server Distributed Replay as a replay mechanism. Some modern disk arrays can actually detect the patterns underneath synthetic storage testing, and these tests are less effective on those arrays. Be careful!
How to Use DiskSpd Batch
First, download DiskSpd, and extract it to your hard drive on the server that you wish to test. Read the documentation that comes with it.
Next, find the subdirectory that matches your system architecture (32 or 64-bit). This path becomes your location to the DiskSpd executable.
Download the script and unpack into a folder on your file system.
From an elevated PowerShell prompt, execute the script with the following parameters that you specify.
Syntax:
| Parameter | Description |
| -Time | Duration for each test cycle, measured in seconds |
| -DataFile | Path and filename for the workload file |
| -DataFileSize | Workload file size, in the format “500M” for 500MB, or “10G” for 10GB |
| -BlockSize | NTFS target workload block size, in the format “4K” for 4KB, or “1M” for 1MB |
| -OutPath | Results output file location (output file is automatically named) |
| -SplitIO | “True” tests permutations of read and write tests in the same test cycle, in increments of 10%. “False” only tests 100% read or write test cycles. |
| -AllowIdle | So as not to overwhelm a storage device’s ability to flush inbound I/O to disk, pause for 20 seconds between test cycles |
| -EntropySize | Add random data instead of zeroes to the workload file to simulate more real-world test examples, in the format “1G” for 1GB |
Example:
A normal test cycle might resemble the following screenshot.

As the script executes, it approximates the total test batch runtime, and shows you the progress with the current test number out of the overall batch.

During the tests, the results are stored into an output file in XML format. Once completed, the test batch fetches this XML file and extracts the important information into a CSV file for you to review and analyze at a later date.

The CSV file can then be opened in your favorite program, and the results from each test can be reviewed. The columns you will find most interesting are:
- WriteRatio
- IsRandom
- MB/s
- IOps
- Read MB/s
- Read IOps
- Write MB/s
- Write IOps
- Read and write latencies, broken out by percentile
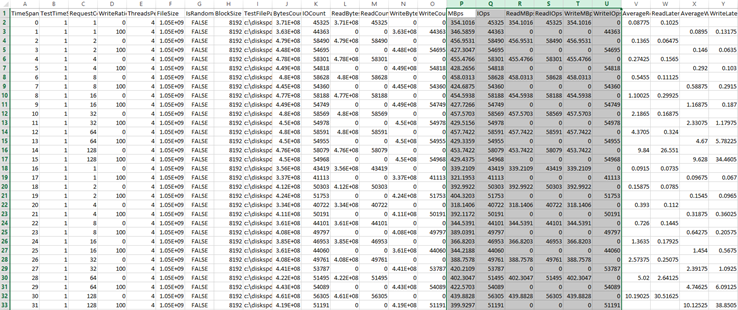
Enjoy!
Change History
| Version | Change Details |
| 1.0.0 | Initial Release (2015.04.29) |
| 1.0.1 | Removed self-elevating detection (2015.08.23) |
| 1.0.2 | Corrected ReadMB XML extractor (2015.09.08) |
| 1.0.3 | Added parameter to specify block size (2015.09.26) |
| 1.0.4 | Updated diskspd.exe call for relative path handling (2016.01.17) |
| 1.0.5 | Added entropy parameter and fixed bug in diskspd XML output with random/sequential test label (2016.07.09) |
Enjoy this free utility from Heraflux, and please send us any feedback that you have!